Bence Tóth and Mihály Fazekas of the Corruption Research Center Budapest (CRCB) contribute the following guest post:
As several earlier posts on this blog have discussed (see, for example, here, here, and here), collusion and corruption in public procurement is a significant problem, one that is extremely difficult to detect and combat. The nature of public procurement markets makes collusion easier to sustain, as pay-offs are higher (demand is often inelastic due to the auction mechanisms used), administrative costs increase entry barriers, and the transparency of procurement contract awards–often intended as an anticorruption device–can actually make it easier for cartel members to monitor one another and punish cheating. Law enforcement agencies have tried various techniques for breaking these cartels, for example by offering leniency to the first company that “defects” on the other cartel members by exposing the collusive arrangement. However, although leniency policies have sometimes proven to be an effective tool to fight coordinated company behavior, the efficacy of this approach is limited given the relative unlikelihood that the government will ever acquire convincing evidence of collusion absent such a defection by an insider. Hence, there is great need for alternative methods to identify collusive rings and guide tradition investigation.
In many markets, using quantitative indicators to detect collusion has not been feasible, as gathering meaningful tender-level data (or even market-level data) is too costly, or simply impossible. However, in the case of public procurement markets, there is a huge amount of publicly available data, which makes the use of “Big Data” techniques to pinpoint collusion-related irregularities more feasible. Indeed, in collaboration with our colleagues at CRCB, we have developed a simple, yet novel approach for detecting collusive behavior.
Our method works by using indirect and direct measures for three things:
- The elementary collusive techniques (e.g. withholding bids),
- The market structure that typically emerges in the presence of such collusion (e.g. a concentrated market), and
- the forms of rent-sharing associated with collusion (e.g. subcontracting).
For instance, withholding bids is an elementary collusion technique, which can be measured at the tender level (the number of bids received), the company level (the number of bids per contract won by that company), and the market level (the average number of bids per tender). Furthermore, the evolution of market shares can also provide evidence of coordinated bidding (e.g. extremely stable market shares, or sudden concentration of a market when a collusive ring is formed).
Nevertheless, these individual indicators have to be analyzed in relation to each other, in order to reflect the risk of collusion among bidders. For example, one of the most straightforward ways to mimic competition while in fact coordinating bidding is for one member of the cartel to be selected as the “winner” for a particular contract, with all the other companies in the cartel deliberately submitting losing bids (bids that are too high, or are defective for some other reason). Such collusion can be hard to detect when focusing only on particular indicators in isolation, but considering a set of indicators together can be revealing. For instance, if we observe (1) a dominant company that usually wins a particular sort of bid, (2) a set of bidding, but always losing companies, as the usual other participants in those tenders, (3) increased market concentration over time, (4) non-competitive offer price distributions (very low variation of offer prices or constant difference between first and second price etc.), and/or (5)frequent use of subcontractors, then this combination of factors can indicate a potential bid-rigging scheme.
Such a scheme can be seen from a network analysis perspective in the figure below. Although the figure may somewhat difficult to interpret on its own, it provides a graphical representation of the relationship between different firms that bid on public tenders. Each circle represents a company, with the size of the circle indicating the number of tenders that company won. The lines connecting the circles indicate that these two companies both bid on the same tender, with the thickness of the line indicating the frequency with which this occurred. The color (green or red) indicates whether the firm is in a “cut point” position — that is, whether it is the only link between the losing companies and other parts of the network (such that, if the “cut point” firm were eliminated, the network would split into two sub-networks without any overlap, i.e. without any firms from the two sub-networks ever bidding on the same contracts). Note from the graph that companies seem to companies seem to benefit from being in a cut-point position, as they win significantly more tenders than the average, which supports the idea of deliberate attempts by a cartel to mimic competition. Interestingly these firms are also more likely to subcontract than the other firms in the market.
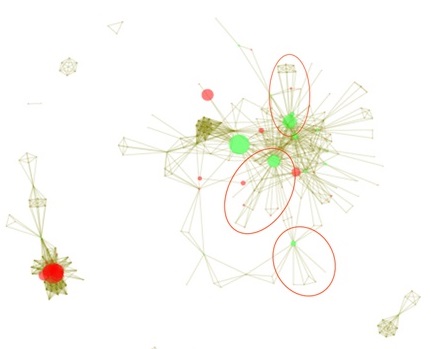
[Note: Vertex=bidding company (size=number of tenders won), Edge=co-bidding (width=number of tenders); Color=position (green=cut-point); data from the Hungarian public procurement market, 2009.]
The above explained set-up is just one example of many possible collusive schemes. A thorough understanding of different coordination schemes is indispensable for generating valid, and widely useable empirical tools that can complement traditional investigative techniques in the field of cartel detection.

very interesting. I’m thinking of how to apply the Brazilian case. Where there is large companies financianado political parties through public contract.
I’m interested in the figure you post, what tools did you use to make it? I’m learning Pyhton for data analysis, and find an igraph library, but its too difficult for me.
We used igraph in R which is certainly similar to igraph in Pyhton. Unfortunately, more user friendly social network analysis tools such as Ucinet are not good for this kind of analysis as they cannot handle large datasets.